
A Feedforward neural network is a type of artificial neural network where information flows in a single direction, from the input layer through one or more hidden layers to the output layer. The training process of a feedforward neural network involves adjusting the weights and biases of the network to minimize the difference between the predicted output and the desired output. Here’s an overview of the training process:
- Data Preparation:
- The training process starts with preparing a dataset that consists of input data and corresponding target output values.
- The dataset is typically divided into training and validation sets, where the training set is used to update the network’s weights, and the validation set is used to assess the model’s performance during training.
- Initialization:
- The weights and biases of the neural network are initialized randomly or with predetermined values.
- Proper initialization is important to avoid convergence to suboptimal solutions.
- Forward Propagation:
- In the forward propagation step, the input data is fed into the neural network, and the outputs of each neuron in the network are computed.
- The outputs of the neurons in each layer serve as inputs to the neurons in the subsequent layer until the output layer is reached.
- The activation function is applied to each neuron’s input to introduce non-linearity and allow the network to learn complex relationships.
- Loss Calculation:
- After the forward propagation, the predicted outputs of the network are compared with the desired output values from the dataset.
- A loss function is used to measure the difference between the predicted outputs and the targets.
- Common loss functions include mean squared error, categorical cross-entropy, or binary cross-entropy, depending on the nature of the problem.
- Backpropagation:
- Backpropagation is the core of the training process in a feedforward neural network.
- It involves calculating the gradients of the loss function with respect to the network’s weights and biases.
- The gradients are then used to update the weights and biases in a way that minimizes the loss function.
- Weight Update:
- The weights and biases of the network are updated using optimization algorithms such as gradient descent, stochastic gradient descent, or variations like Adam or RMSprop.
- The magnitude and direction of the weight updates are determined by the gradients calculated during the backpropagation step.
- The learning rate, which determines the step size of the weight updates, is an important hyperparameter to be tuned.
- Iterative Training:
- Steps 3 to 6 (forward propagation, loss calculation, backpropagation, and weight update) are repeated iteratively for multiple epochs or until a stopping criterion is met.
- Each iteration helps the network gradually adjust its weights and biases to minimize the loss and improve its predictive performance.
- Validation and Evaluation:
- After training, the performance of the trained network is evaluated on the validation set or a separate test set to assess its generalization ability.
- Metrics such as accuracy, precision, recall, or mean squared error are used to evaluate the model’s performance.
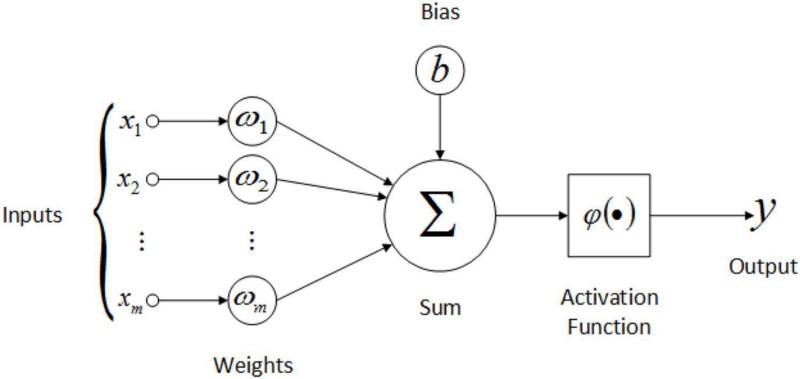
By iteratively adjusting the network’s weights and biases through forward propagation and backpropagation, the neural network gradually learns the underlying patterns and relationships in the training data. This enables the network to make accurate predictions on unseen data during the evaluation phase.